Bài 5: Dự báo giá cổ phiếu với GBM
Dự báo giá cổ phiếu 90 ngày bằng mô hình GBM. Cách dùng dữ liệu thực tế để 'đọc vị' thị trường.
Chúng ta đã đi qua một hành trình dài từ những bước đi ngẫu nhiên của Random Walk đến dòng chảy liên tục của Brownian Motion. Nhưng lý thuyết sẽ chỉ là lý thuyết nếu chúng ta không thể áp dụng vào thực tế sinh động. Liệu chỉ số S&P 500 hay giá cổ phiếu Apple có thực sự tuân theo quy luật mà các nhà toán học đã đặt ra?
Trong bài viết này, chúng ta sẽ tạm rời xa các công thức khô khan để bắt tay vào làm việc với dữ liệu thực tế. Chúng ta sẽ kiểm chứng xem thị trường có “chuẩn” như chúng ta nghĩ, học cách đo lường “linh hồn” của cổ phiếu qua bộ tham số \(\mu, \sigma\), và cuối cùng là dùng Python/Excel để dự đoán tương lai ngắn hạn trong 90 ngày tới.
Trong trang này:
- 1. Kiểm chứng phân phối chuẩn — Normality Test
- 2. Hiệu chuẩn mô hình — Calibration
- 3. Dự báo — Predicting
- 4. Tóm tắt và thảo luận
1. Kiểm chứng phân phối chuẩn — Normality Test
Trước khi áp dụng mô hình vào thực tế, chúng ta cần trả lời một câu hỏi nền tảng: dữ liệu thực tế có “chuẩn” như lý thuyết yêu cầu không? Bachelier giả định lợi nhuận tuyệt đối (absolute return), còn GBM thì yêu cầu lợi nhuận (log-return) phải tuân theo phân phối chuẩn. Hãy cùng kiểm chứng điều này với dữ liệu lịch sử.
1.1. Thu thập dữ liệu
Để thực hiện, chúng ta cần dữ liệu lịch sử chất lượng, tốt nhất là giá đóng cửa điều chỉnh (adjusted close) đã loại bỏ tác động của chia tách (split) và cổ tức (dividend).
Có rất nhiều nguồn cho phép bạn truy cập miễn phí dữ liệu lịch sử giao dịch chứng khoán. Các lựa chọn này trải dài từ việc tải file .csv thủ công trên trang web cho đến các API mạnh mẽ giúp tự động lấy dữ liệu dành cho lập trình viên. Dưới đây là một vài nguồn dữ liệu miễn phí tốt nhất năm 2026 để bạn tham khảo.
Tải xuống thủ công cho người mới
Nếu bạn chỉ cần một file .csv để mở trong Excel hoặc Google Sheets, đây là những lựa chọn tốt nhất:
-
Yahoo Finance: Vẫn được coi là “tiêu chuẩn vàng” cho việc tải dữ liệu nhờ tính bao quát thị trường và hoàn toàn miễn phí. Nó cung cấp dữ liệu của hầu hết các sàn chứng khoán lớn trên thế giới và cả ở Việt Nam. Cách làm: tìm kiếm mã chứng khoán, ví dụ AAPL (Apple Inc.), nhấp vào tab Historical Data, chọn khoảng thời gian và nhấn Download.
-
Investing.com: Cung cấp cơ sở dữ liệu khổng lồ về cổ phiếu toàn cầu, các chỉ số, cũng như hàng hóa. Cách làm: tìm kiếm mã chứng khoán, ví dụ JPM (JPMorgan Chase & Co.), đi đến tab Historical Data và bạn có thể Download dữ liệu trực tiếp.
API cho lập trình viên
-
Alpha Vantage: Đây là API phổ biến nhất vì nó cung cấp hầu hết mọi thứ từ giá cổ phiếu, ngoại hối (Forex), tiền điện tử (Crypto) đến các chỉ báo kỹ thuật (RSI, MACD…). Gói miễn phí giới hạn khoảng 25 yêu cầu/ngày, phù hợp để làm các dự án nhỏ, học tập hoặc nghiên cứu.
-
Polygon.io: Nếu bạn cần dữ liệu cực nhanh và chính xác cho thị trường chứng khoán Mỹ, Polygon là lựa chọn hàng đầu. Gói miễn phí cho phép truy cập dữ liệu lịch sử trong vòng 2 năm với giới hạn 5 yêu cầu/phút.
Nên lấy dữ liệu trong khoảng 2 đến 5 năm để có đủ cỡ mẫu (sample size) cho các kiểm định thống kê, nhưng không quá xa để tránh việc cấu trúc thị trường đã thay đổi quá nhiều.
1.2. Mô tả dữ liệu
Để thuận tiện cho bài viết, tôi đã chuẩn bị sẵn dữ liệu thực tế của 4 mã cổ phiếu blue-chips trên sàn S&P500 như AAPL (Apple Inc.), JPM (JPMorgan Chase & Co.), JNJ (Johnson & Johnson), XOM (Exxon Mobil Corp.) rất phù hợp để so sánh hai mô hình Bachelier và GBM. Bạn có thể download dữ liệu tại đây 5_market_data.zip.
market_data bao gồm dữ liệu theo ngày (daily) trong 2 năm gần nhất, với giá mở cửa (open), cao nhất (high), thấp nhất (low), đóng cửa (close), khối lượng giao dịch (volume) và một số thông tin khác.
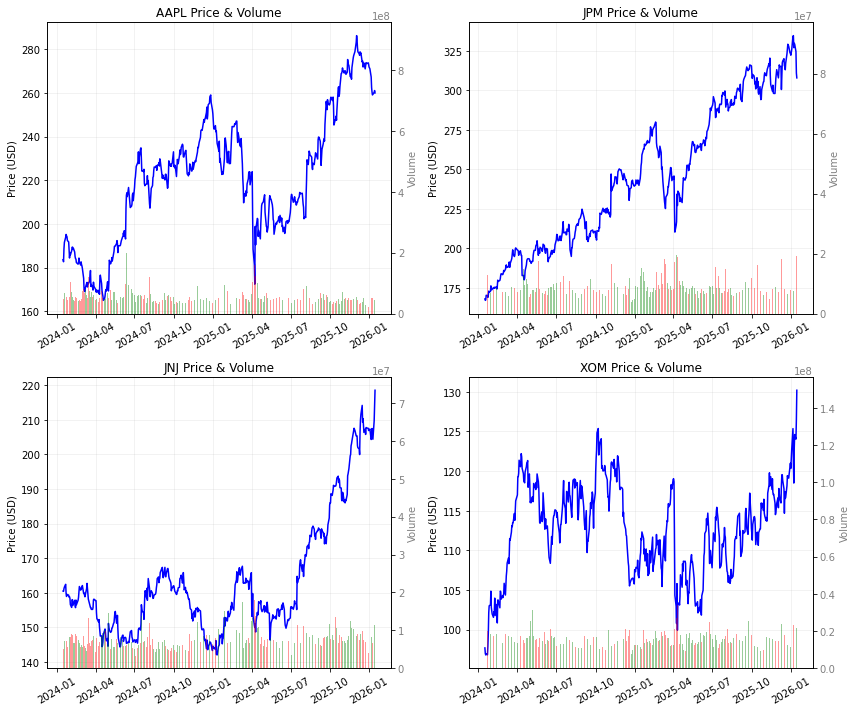
Nhìn vào biểu đồ thực tế, bạn sẽ thấy những đoạn giá bỗng dưng “dốc đứng” như vách núi, hay thậm chí là “đứt đoạn” tạo thành một khoảng trống. Xin chúc mừng: bạn vừa tận mắt chứng kiến những “bước nhảy giá” (jump) trong thị trường tài chính đấy!
Những bước nhảy này từ đâu mà ra? Đó có thể là một bản báo cáo lợi nhuận “khủng” khiến nhà đầu tư phấn khích. Một tin tức vĩ mô bất ngờ từ chính phủ. Hay đơn giản là một sự kiện đột xuất của doanh nghiệp khiến mọi người “trở tay không kịp” vào sáng hôm sau. Hãy để ý các cột volume (xanh/đỏ) ở dưới. Một “bước nhảy giá” thường đi kèm với một cột volume cao ngất ngưởng. Nó giống như việc bạn hét lớn và có cả một đám đông hàng ngàn người cùng hò reo theo vậy – đó chính là sự “xác nhận” cho một xu hướng mới đã bắt đầu.
Hãy thử dùng GBM để mô phỏng giá cổ phiếu Apple, từ đó xem liệu mô hình này có bắt được những “cú nhảy giá” đột ngột như thực tế hay không.
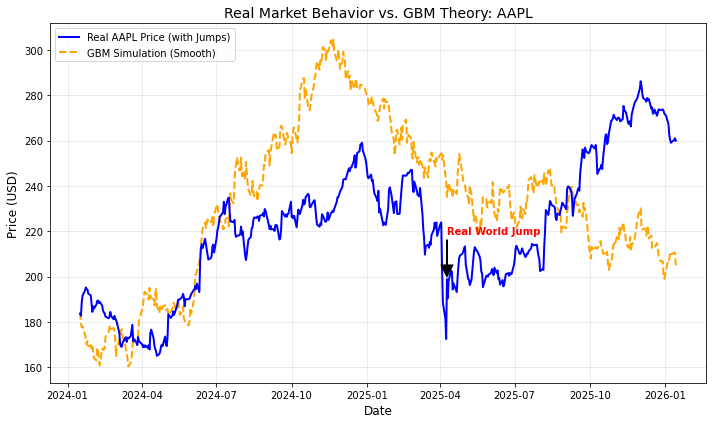
Khi nhìn vào biểu đồ, bạn sẽ thấy một sự thật phũ phàng nhưng đầy thú vị. Đường GBM (màu cam đứt đoạn) sẽ trông rất “hiền”, nó dao động ngẫu nhiên “êm đềm” (smooth) như một dòng sông, tăng giảm nhẹ nhàng từng chút một. Đường giá thực tế AAPL (màu xanh) trông rất “gai góc” với những đoạn gãy khúc hoặc vọt lên/xuống rất “gắt” (jump).
Bạn thấy đó giữa “lý thuyết màu hồng” và “thực tế màu xám” có những khoảng cách rất thú vị. GBM bảo vệ bạn tốt khi “trời quang mây tạnh”, nhưng khi có “bão” (những cú nhảy giá đột ngột), nó thường bị “đơ ra” vì những cú nhảy đó không nằm trong công thức toán học của nó. Đó là lý do tại sao các chuyên gia tài chính sau này phải “tô điểm” thêm cho lý thuyết bằng các mô hình như Jump-Diffusion (GBM cộng thêm các cú nhảy) để thực tế bớt “xám” và lý thuyết bớt “hồng” đi một chút.
1.3. Kiểm chứng với Python
Để kiểm tra dữ liệu có “chuẩn” không, chúng ta sẽ kiểm tra nhanh bằng trực quan qua biểu đồ Histogram, Q-Q Plot sau đó bằng các chỉ số định lượng Skewness, Kurtosis.
Kiểm chứng với cổ phiếu AAPL (Apple Inc.)
Bạn có thể chạy code trên Google Colab cho cổ phiếu AAPL (Apple Inc.).
![]()
Nếu chạy local trên máy tính của bạn, market_data cần đặt cùng thư mục chứa code Python. Bạn có thể thay thế ticker = "AAPL" bằng "JPM", "JNJ", "XOM" để chạy kiểm định với các mã cổ phiếu khác.
Hàm pd.read_csv(file_path) giúp đọc file .csv và gán dữ liệu vào dataframe — một container trong thư viện pandas. Hàm pd.to_datetime giúp chuẩn hóa dữ liệu thời gian sang định dạng ngày giờ.
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
import os
# --- CONFIGURATION ---
ticker = "AAPL"
folder_name = "market_data"
# --- 1. Load Historical Data ---
# This code for run in local
file_path = os.path.join(folder_name, f"{ticker}.csv")
try:
# Read Csv file from a local
print("Loading data from local CSV...")
df = pd.read_csv(file_path)
# Ensure Date is datetime if loading from CSV
df['timestamp'] = pd.to_datetime(df['timestamp'])
print("Success!")
except Exception as e:
print(f"Error loading file: {e}")
Kiểm tra mẫu (sample) đầu vào, ta có 502 dữ liệu theo ngày (daily) tương đương với gần 2 năm dữ liệu (mỗi năm có 252 ngày giao dịch).
# Inspect data
df
open high low close volume vwap timestamp transactions otc
0 182.160 184.26 180.934 183.63 65603041.0 182.8825 2024-01-16 05:00:00 767284 NaN
1 181.270 182.93 180.300 182.68 47317433.0 181.9201 2024-01-17 05:00:00 594632 NaN
2 186.090 189.14 185.830 188.63 78005754.0 187.9375 2024-01-18 05:00:00 787235 NaN
3 189.330 191.95 188.820 191.56 68902985.0 190.6151 2024-01-19 05:00:00 682664 NaN
4 192.300 195.33 192.260 193.89 60133852.0 193.9891 2024-01-22 05:00:00 718108 NaN
... ... ... ... ... ... ... ... ... ...
497 257.020 259.29 255.700 259.04 50419337.0 257.4496 2026-01-08 05:00:00 764090 NaN
498 259.075 260.21 256.220 259.37 39996967.0 258.6804 2026-01-09 05:00:00 649745 NaN
499 259.160 261.30 256.800 260.25 45263767.0 260.0061 2026-01-12 05:00:00 664531 NaN
500 258.720 261.81 258.390 261.05 45601262.0 260.3489 2026-01-13 05:00:00 599894 NaN
501 259.490 261.82 256.710 259.96 39934470.0 259.2345 2026-01-14 05:00:00 611582 NaN
502 rows × 9 columns
Ta tính lợi nhuận tuyệt đối price_diffs cho Bachelier bằng giá ngày hôm sau trừ giá ngày hôm trước \(\Delta S_t = S_t - S_{t-1}\) — hàm diff() trong code. Với GBM, lợi nhuận log_returns được tính theo công thức \(\Delta S_t = \ln\left(\frac{S_t}{S_{t-1}}\right)\) — hàm np.log trong code.
Hàm dropna() giúp loại bỏ dữ liệu NaN trong mẫu. Dòng đầu tiên sẽ bị loại bỏ do không có dữ liệu trước đó để tính lợi nhuận.
# --- 2. Calculate Return ---
# Create a new DataFrame with only 'timestamp' and 'close'
df_prices = df[['timestamp', 'close']].copy()
# GBM Model (Log-Returns)
# Formula: ln(P_t / P_{t-1})
log_returns = np.log(df_prices['close'] / df_prices['close'].shift(1)).dropna()
df_prices['log_returns'] = log_returns
# Bachelier Model (Absolute Price Changes)
# Formula: P_t - P_{t-1}
price_diffs = df_prices['close'].diff().dropna()
df_prices['price_diffs'] = price_diffs
Ta thử kiểm tra tính toán lợi nhuận tuyệt đối price_diffs và lợi nhuận log_returns.
# Inspect the result
df_prices
timestamp close log_returns price_diffs
0 2024-01-16 05:00:00 183.63 NaN NaN
1 2024-01-17 05:00:00 182.68 -0.005187 -0.95
2 2024-01-18 05:00:00 188.63 0.032051 5.95
3 2024-01-19 05:00:00 191.56 0.015414 2.93
4 2024-01-22 05:00:00 193.89 0.012090 2.33
... ... ... ... ...
497 2026-01-08 05:00:00 259.04 -0.004968 -1.29
498 2026-01-09 05:00:00 259.37 0.001273 0.33
499 2026-01-12 05:00:00 260.25 0.003387 0.88
500 2026-01-13 05:00:00 261.05 0.003069 0.80
501 2026-01-14 05:00:00 259.96 -0.004184 -1.09
Tiếp theo, ta vẽ biểu đồ Histogram và Q-Q Plot để kiểm tra phân phối chuẩn một cách trực quan.
# --- 3. Plot Histograms, Q-Q Plot ---
# Create a figure with 2 rows and 2 columns
plt.figure(figsize=(12, 10))
# --- GBM MODEL (LOG RETURNS) ---
# Plot 1: Histogram for Log Returns
plt.subplot(2, 2, 1)
x_vals_log = np.linspace(log_returns.min(), log_returns.max(), 100)
# Use mu and sigma calculated from log_returns
mu_l, sigma_l = stats.norm.fit(log_returns)
pdf_vals_log = stats.norm.pdf(x_vals_log, mu_l, sigma_l)
plt.hist(log_returns, bins=50, density=True, alpha=0.6, color='blue', label="Empirical Log Returns")
plt.plot(x_vals_log, pdf_vals_log, 'r--', lw=2, label='Normal Fit (GBM)')
plt.title(f"GBM Model: Log Returns Distribution ({ticker})", fontsize=12)
plt.xlabel("Log Returns", fontsize=10)
plt.ylabel("Density", fontsize=10)
plt.legend()
plt.grid(axis='y', alpha=0.3)
# Plot 2: Q-Q Plot for Log Returns
plt.subplot(2, 2, 2)
log_returns_std = (log_returns - log_returns.mean()) / log_returns.std()
stats.probplot(log_returns_std, dist="norm", plot=plt)
plt.title("Q-Q Plot: Log Returns (Check for Fat Tails)", fontsize=12)
plt.xlabel("Theoretical Quantiles", fontsize=10)
plt.ylabel("Ordered Values", fontsize=10)
plt.grid(True, alpha=0.3)
# --- BACHELIER MODEL (PRICE DIFFERENCES) ---
# Plot 3: Histogram for Price Differences
plt.subplot(2, 2, 3)
x_vals_abs = np.linspace(price_diffs.min(), price_diffs.max(), 100)
# Use mu and sigma calculated from price_diffs
mu_a, sigma_a = stats.norm.fit(price_diffs)
pdf_vals_abs = stats.norm.pdf(x_vals_abs, mu_a, sigma_a)
plt.hist(price_diffs, bins=50, density=True, alpha=0.6, color='green', label="Empirical Price Diffs")
plt.plot(x_vals_abs, pdf_vals_abs, 'r--', lw=2, label='Normal Fit (Bachelier)')
plt.title(f"Bachelier Model: Absolute Price Diffs ({ticker})", fontsize=12)
plt.xlabel("Price Difference ($)", fontsize=10)
plt.ylabel("Density", fontsize=10)
plt.legend()
plt.grid(axis='y', alpha=0.3)
# Plot 4: Q-Q Plot for Price Differences
plt.subplot(2, 2, 4)
price_diffs_std = (price_diffs - price_diffs.mean()) / price_diffs.std()
stats.probplot(price_diffs_std, dist="norm", plot=plt)
plt.title("Q-Q Plot: Price Diffs (Check for Fat Tails)", fontsize=12)
plt.xlabel("Theoretical Quantiles", fontsize=10)
plt.ylabel("Ordered Values", fontsize=10)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
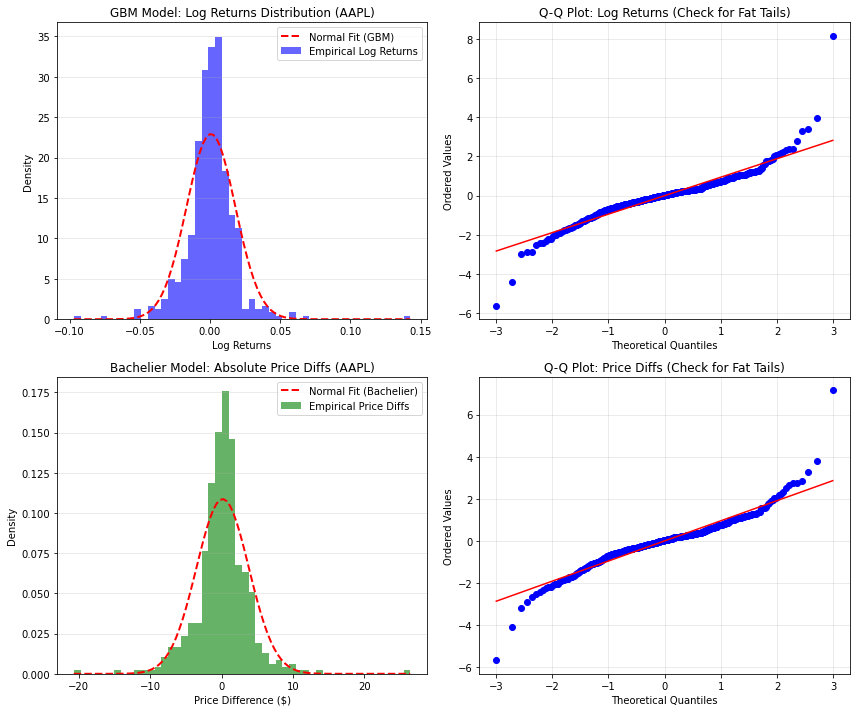
Biểu đồ cho thấy dữ liệu thực tế của Apple (cả absolute return và log-return) không tuân theo phân phối chuẩn một cách hoàn hảo: ta thấy hiện tượng “đuôi béo” (Fat Tails) và “đỉnh nhọn” (Leptokurtosis).
Biểu đồ Histogram cho thấy phần đỉnh vọt lên cao và nhọn nhiều hơn đường màu đỏ. Quan trọng hơn, phần đuôi ở biểu đồ Q-Q Plot bị uốn cong ra xa đường chéo \(45^\circ\) ở cả hai đầu, minh chứng cho việc các biến động cực đoan (sập sàn hoặc tăng trần) xảy ra thường xuyên hơn so với dự báo lý thuyết.
Cuối cùng, ta tính toán các chỉ số thống kê để kiểm tra phân phối chuẩn.
# --- 4. Calculate Statistics ---
def display_stats(data, label):
s = stats.skew(data)
k = stats.kurtosis(data)
jb_stat, p_val = stats.jarque_bera(data)
print(f"--- Statistics: {label} ---")
print(f"Skewness: {s:.4f}")
print(f"Kurtosis: {k:.4f}")
print(f"Jarque-Bera P-value: {p_val:.4e}")
print("-" * 40)
# Print metrics for comparison
print(f"--- Normality Test: {ticker} ---")
display_stats(log_returns, "GBM (Lognormal Fit)")
display_stats(price_diffs, "Bachelier (Normal Fit)")
--- Normality Test: AAPL ---
--- Statistics: GBM (Lognormal Fit) ---
Skewness: 0.6364
Kurtosis: 11.7107
Jarque-Bera P-value: 0.0000e+00
----------------------------------------
--- Statistics: Bachelier (Normal Fit) ---
Skewness: 0.2830
Kurtosis: 8.0102
Jarque-Bera P-value: 0.0000e+00
----------------------------------------
Cả hai mô hình đều cho thấy:
-
Skewness lệch dương: GBM \((0.6364)\) có độ lệch dương rõ rệt, Bachelier \((0.2830)\) đối xứng hơn một chút nhưng vẫn lệch dương. Điều này cho thấy trong giai đoạn này, Apple có xu hướng xuất hiện các phiên tăng điểm đột biến mạnh nhiều hơn là các phiên giảm sâu.
-
Kurtosis cực cao: Chỉ số Kurtosis của GBM là \(11.71\) và Bachelier là \(8.01\). Trong phân phối chuẩn lý tưởng, chỉ số này (excess kurtosis) bằng \(0\). Điều này xác nhận hiện tượng “đỉnh nhọn” mà ta quan sát được trong Histogram.
-
Kiểm định Jarque-Bera: \(P-value = 0.0000e+00\) gần như bằng \(0\), tương đương việc bác bỏ hoàn toàn giả thuyết cho rằng lợi nhuận của Apple tuân theo phân phối chuẩn.
Kiểm chứng với cổ phiếu khác
Không có một mô hình nào (dù là GBM hay Bachelier) hoàn toàn đúng cho mọi loại tài sản. Cổ phiếu công nghệ có thể vi phạm các giả định phân phối chuẩn do biến động cực đoan, nhưng cổ phiếu năng lượng, tài chính hay y tế thì sao? Chúng ta cùng thực hiện kiểm định cho các mã cổ phiếu còn lại.
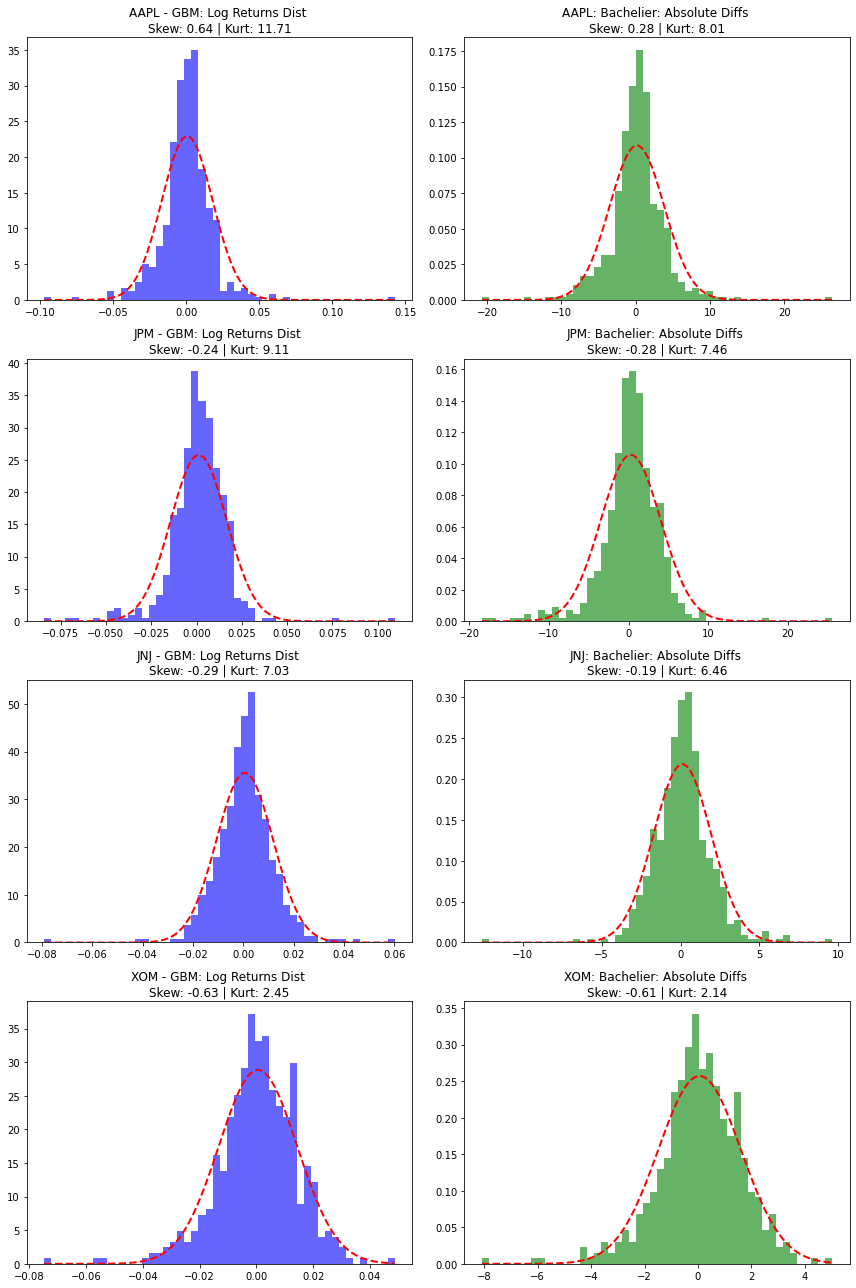
Nhìn vào biểu đồ, ta thấy cả 4 cổ phiếu đều có hiện tượng chung “đuôi béo” và “đỉnh nhọn”.
-
AAPL (Apple Inc.): Cổ phiếu công nghệ (Technology) tăng trưởng mạnh. AAPL có đỉnh nhọn nhất, và độ lệch dương lớn cho thấy có nhiều phiên tăng điểm bùng nổ do tin tức sản phẩm hoặc kết quả kinh doanh.
-
JPM (JPMorgan Chase & Co.): Cổ phiếu tài chính (Financials) nhạy cảm với lãi suất và các chu kỳ kinh tế. Histogram của JPM có đuôi lệch trái so với AAPL, phản ánh các đợt sụt giảm mạnh khi thị trường lo ngại về lãi suất hoặc khủng hoảng tài chính.
-
JNJ (Johnson & Johnson): Cổ phiếu y tế (Healthcare) biến động thấp, cổ tức ổn định. JNJ là cổ phiếu phòng thủ, thường được kỳ vọng bám sát đường cong phân phối chuẩn nhất (đỉnh bớt nhọn và đuôi ngắn hơn).
-
XOM (Exxon Mobil Corp.): Cổ phiếu năng lượng (Energy) phụ thuộc vào giá dầu thô, biến động rất cao và không ổn định. Histogram của XOM mặc dù ít nhọn nhưng lại có độ lệch trái lớn nhất \((Skewness = -0.63)\) phản ánh sự biến động (volatility) rất lớn.
Việc cả 4 mã cổ phiếu đều vi phạm giả thuyết phân phối chuẩn cảnh báo các nhà đầu tư rằng: thị trường thực tế luôn có rủi ro và các cú sốc ngẫu nhiên mà các mô hình toán học không thể bao quát hết được. Nếu chỉ dựa vào phân phối chuẩn để quản trị rủi ro, họ sẽ đánh giá thấp khả năng xảy ra các sự kiện sụp đổ hoặc tăng trưởng đột biến.
1.4. Kiểm chứng với Excel/VBA
Bạn có thể download file Excel bên dưới để bắt đầu thực hành.
Worksheet 1 “Normality Test”: Trang tính này phân tích lợi nhuận của cổ phiếu Apple để kiểm tra tính phân phối chuẩn thông qua biểu đồ Histogram, các chỉ số Skewness, Kurtosis và kiểm định Jarque-Bera.
Công thức tại ô C8 và D8 như sau.
=B8 - B7
=LN(B8/B7)
Trong đó B8 là giá ngày hôm nay, B7 là giá ngày hôm trước. Đây chính là công thức tính absolute return và log-return theo ngày (daily) cho cổ phiếu Apple.
Từ dữ liệu lợi nhuận, ta vẽ Histogram thủ công trong Excel.
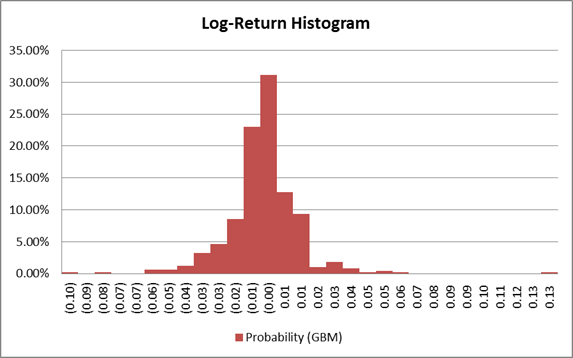
Biểu đồ cho thấy log-return của Apple không tuân theo phân phối chuẩn một cách hoàn hảo mà có “đỉnh nhọn” và “đuôi béo” về hai phía.
Trong Excel, để tính Skewness, Kurtosis ta chỉ cần gọi trực tiếp hàm SKEW() và KURT(). Kiểm định Jarque-Bera phức tạp hơn, nhưng ta có thể tính đại lượng thống kê (test statistic) theo công thức \(JB = \frac{n}{6} \left( S^2 + \frac{1}{4}(K)^2 \right)\) trong đó \(n\) là số lượng mẫu, \(S\) là Skewness, \(K\) là Excess Kurtosis; và dựa vào giá trị này để đưa ra kết luận. Khác với \(P-value\) như trong phần Python, \(B\) càng gần \(0\), dữ liệu càng gần với phân phối chuẩn.
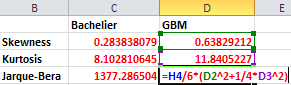
Từ Hình 6, ta bác bỏ giả thuyết dữ liệu thực tế của Apple là chuẩn, với Skewness, Kurtosis, và đại lượng thống kê Jarque-Bera đều lệch xa \(0\).
2. Hiệu chuẩn mô hình — Calibration
2.1. Hiệu chuẩn là gì?
Sau khi đã “khám sức khỏe” cho dữ liệu ở Phần 1 và chấp nhận những sai số nhỏ, chúng ta sẽ bước vào giai đoạn quan trọng nhất hiệu chuẩn (calibration).
Hiệu chuẩn thực chất là việc chúng ta nhìn vào dữ liệu quá khứ để tìm ra bộ thông số cốt lõi nhằm thiết lập “động cơ” cho mô phỏng tương lai. Hãy tưởng tượng mỗi cổ phiếu là một vận động viên chạy marathon. Để dự đoán vận động viên đó sẽ chạy được bao xa trong tương lai, bạn cần biết “tốc độ trung bình” và “nhịp thở/độ bền” của họ dựa trên các cuộc đua trước đó. Trong mô hình Bachelier và GBM, chúng ta cần tìm \(\mu\) (drift) và \(\sigma\) (volatility).
-
Drift \((\mu)\) – “động cơ” đẩy giá đi lên. Drift đại diện cho xu hướng tăng trưởng trung bình của cổ phiếu. Nếu bạn giữ cổ phiếu này trong dài hạn, bạn kỳ vọng nó sinh lời bao nhiêu mỗi năm? Nếu \(\mu\) dương, giá cổ phiếu có xu hướng tăng trong dài hạn và ngược lại.
-
Volatility \((\sigma)\) – “sóng” rung lắc. Volatility chính là thước đo của rủi ro, cho biết giá cổ phiếu thường xuyên “nhảy múa” quanh mức trung bình mạnh đến mức nào. \(\sigma\) càng cao, các đường mô phỏng sẽ càng “zic-zac” và lan tỏa rộng, thể hiện sự bất ổn cao của thị trường.
2.2. Phương pháp hiệu chuẩn
Trong bài toán này, chúng ta có hai hướng tiếp cận chính để tìm ra \(\mu\) và \(\sigma\). Một bên dựa trên tư duy tài chính thực dụng (Financial Approach), một bên dựa trên nền tảng thống kê toán học khắt khe (MLE).
Trung bình & độ lệch chuẩn (Financial Approach)
Đây là cách tiếp cận phổ biến nhất trong giới tài chính truyền thống vì nó trực quan, dễ hiểu và dễ thực hiện. Các con số \(\mu, \sigma\) đầu ra khớp với những gì nhà đầu tư nhìn thấy trên các trang tin chứng khoán như Bloomberg hay Reuters.
Cách tiếp cận này coi absolute return (Bachelier) hay log-return (GBM) như một chuỗi thời gian (time series) thông thường và áp dụng các công cụ thống kê mô tả cơ bản để tính trung bình và độ lệch chuẩn.
Các bước thực hiện:
- Tính lợi nhuận hàng ngày: \(r_i = S_i - S_{i-1}\) hoặc \(r_i = \ln(S_i / S_{i-1})\).
- Tính trung bình mẫu \((\bar{r})\): Đại diện cho lợi nhuận kỳ vọng hàng ngày của nhà đầu tư.
- Tính độ lệch chuẩn mẫu \((s)\): Đại diện cho rủi ro hàng ngày của nhà đầu tư.
- Annualization: Đây là bước rất dễ nhầm lẫn. Dữ liệu chúng ta vừa tính là theo ngày (daily), nhưng trong mô hình các tham số thường mặc định theo chuẩn đơn vị năm (annually). Để chuyển đổi, chúng ta cần một chút “phép thuật” toán học (\(252\) thể hiện số ngày giao dịch trong một năm):
Ước lượng hợp lý tối đa (MLE Approach)
MLE (Maximum Likelihood Estimation) là một phương pháp thống kê nhằm tìm ra các tham số sao cho “xác suất xảy ra dữ liệu đã quan sát được là cao nhất”.
Các bước thực hiện:
- Thiết lập hàm Log-Likelihood: Chúng ta xây dựng một hàm toán học dựa trên hàm mật độ xác suất (Probability Density Function) của phân phối chuẩn cho toàn bộ chuỗi dữ liệu.
- Tối ưu hóa: Bằng cách lấy đạo hàm và giải phương trình, MLE đưa ra các ước lượng “không chệch” (unbiased) nhất về mặt toán học.
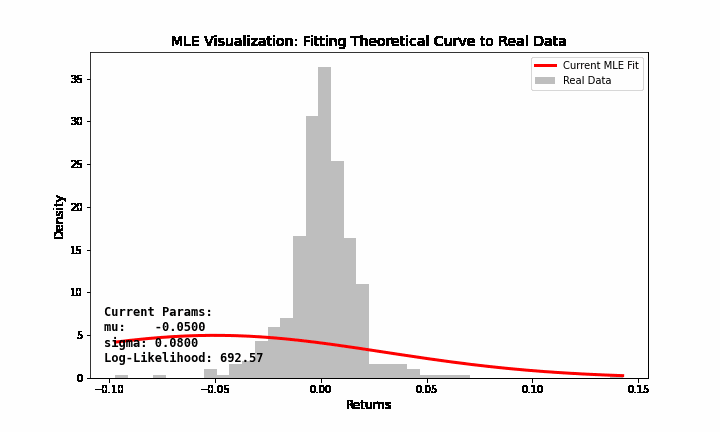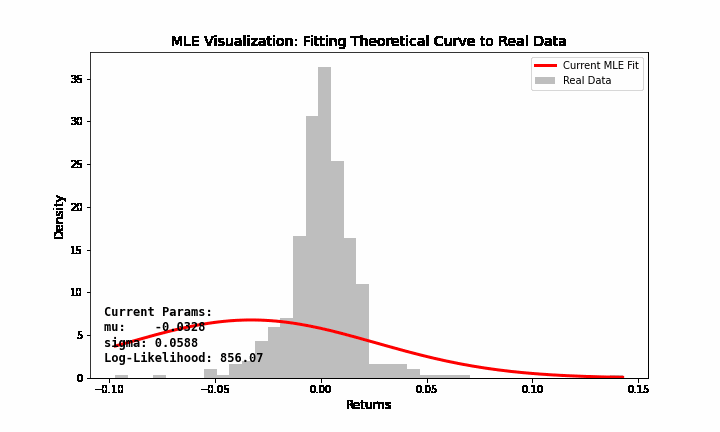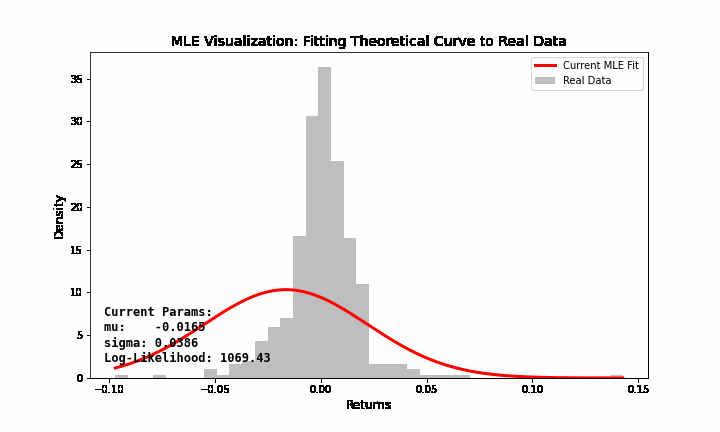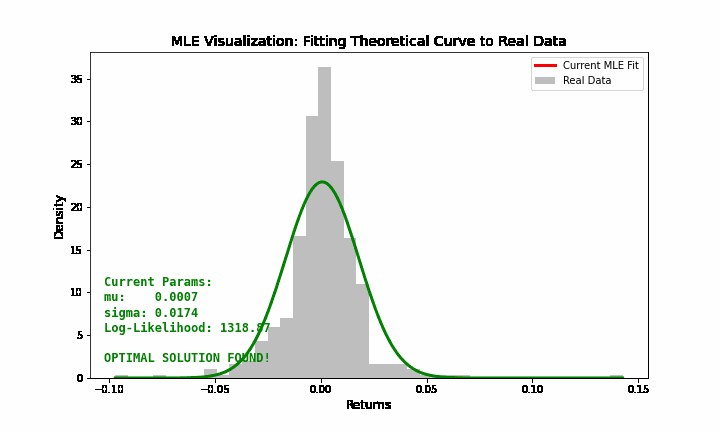
Bạn hãy tưởng tượng bạn có dữ liệu giá chứng khoán với phân phối thực tế như một dải núi nhấp nhô. Bạn biết dải núi đó gần với phân phối chuẩn (hình chuông), nhưng bạn không biết cái chuông này nên rộng bao nhiêu và nằm ở đâu.
Tham số \(\mu\) điều chỉnh cái chuông sang trái hoặc sang phải. Tham số \(\sigma\) điều chỉnh cái chuông béo ra hoặc gầy lại. MLE chính là quá trình bạn “xoay núm vặn” \(\mu\) và \(\sigma\) sao cho cái hình chuông lý thuyết “khớp” nhất với dữ liệu thực tế bạn đang có (Hình 7).
2.3. Hiệu chuẩn với Python
Hàm data.mean() và data.std() là cách tiếp cận “số học” đơn giản mà chúng ta đã học ở trường với mean() để tính trung bình và std() để tính độ lệch chuẩn.
Hàm stats.norm.fit(data) chính là nơi phép màu MLE xảy ra. Hàm này sẽ tự động “xoay núm vặn” để tìm ra \(\mu\) và \(\sigma\) sao cho đường cong lý thuyết khớp nhất với biểu đồ thực tế của bạn.
# --- 5. Calibrattion ---
def display_stats(data, label):
# --- Financial Approach ---
mean_annual = data.mean() * 252
std_annual = data.std() * np.sqrt(252)
# --- MLE Approach ---
mu, sigma = stats.norm.fit(data)
mu_annual = mu * 252
sigma_annual = sigma * np.sqrt(252)
results = pd.DataFrame({
'Metric': ['Annual Drift (mu)', 'Annual Volatility (sigma)'],
'Financial': [mean_annual, std_annual],
'MLE': [mu_annual, sigma_annual]
})
print(f"--- {label} ---")
print(results.to_string(index=False))
print("-" * 48)
# Print metrics for comparison
print(f"--- Calibrattion: {ticker} ---")
display_stats(log_returns, "GBM (Lognormal Fit)")
display_stats(price_diffs, "Bachelier (Normal Fit)")
--- Calibrattion: AAPL ---
--- GBM (Lognormal Fit) ---
Metric Financial MLE
Annual Drift (mu) 0.174843 0.174843
Annual Volatility (sigma) 0.276458 0.276182
------------------------------------------------
--- Bachelier (Normal Fit) ---
Metric Financial MLE
Annual Drift (mu) 38.393533 38.393533
Annual Volatility (sigma) 58.344192 58.285935
------------------------------------------------
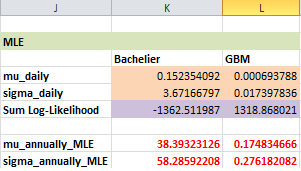
Kết quả cho thấy sự tương đồng rất lớn giữa phương pháp tài chính (Financial) và ước lượng hợp lý tối đa (MLE). Sự chênh lệch \(\sigma\) cực nhỏ giữa hai phương pháp (chỉ \(0.0003\) với GBM, và \(0.058\) với Bachelier) cho thấy dữ liệu thực tế đang tuân thủ khá tốt quy luật toán học mà chúng ta đặt ra. Điều này cho phép chúng ta tự tin sử dụng mô hình mà không lo ngại sai số quá lớn.
Với drift \((\mu)\) đạt mức \(17.48\%\) và volatility \((\sigma)\) hàng năm khoảng \(27.6\%\), chúng ta đã có một bộ “thông số” đáng tin cậy để thiết lập “động cơ” cho các kịch bản mô phỏng Monte-Carlo ở bước tiếp theo.
2.4. Hiệu chuẩn với Excel/VBA
Worksheet 2 “Normality Test”: Trang tính này ước lượng các tham số drift \((\mu)\) và volatility \((\sigma)\) từ dữ liệu thực tế của Apple.
Phương pháp tài chính (Financial), để tính \(\mu\), \(\sigma\) ta chỉ cần gọi trực tiếp hàm AVERAGE() và STDEV.S() trong Excel. Đây chính là trung bình và độ lệch chuẩn mẫu theo ngày, ta cần chuyển về đơn vị theo năm.
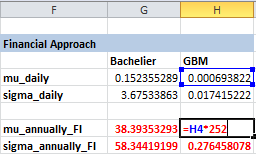
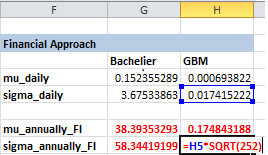
Phương pháp ước lượng hợp lý tối đa (MLE) yêu cầu chạy tính toán nhiều lần để tìm ra bộ tham số tối ưu. Lập trình là bắt buộc để thực thi. Tuy nhiên, Excel có công cụ Solver có thể làm điều này.
Đây là một quá trình “thử và sai” có hệ thống.
-
Với mỗi dữ liệu thực tế của Apple \((-1.2\%, 0.5\%...)\), Excel dùng hàm mật độ xác suất (Probability Density Function) để tính xem điểm đó “cao” bao nhiêu trên đường cong lý thuyết.
-
Chúng ta cộng dồn LN() của chúng. Nếu tổng này càng lớn, nghĩa là đường cong lý thuyết của bạn đang “giải thích” rất tốt dữ liệu thực tế.
-
Solver trong Excel sẽ liên tục thay đổi \(\mu\), \(\sigma\) cho đến khi tổng log-chiều cao (Log-Likelihood) đạt mức cao nhất có thể. Đó chính là lúc đường cong “khớp” nhất.
Ta sử dụng hàm mật độ xác suất (Probability Density Function) tại ô N4 và Q4 như sau.
=NORM.DIST(C4, $K$4, $K$5, FALSE)
=NORM.DIST(D4, $L$4, $L$5, FALSE)
Ta thiết lập giá trị dự đoán ban đầu của \(\mu\), \(\sigma\) tại K4:K5 cho Bachelier và L4:L5 cho GBM (ô màu cam). Tổng Log-Likelihood được tính sẵn với bộ tham số dự đoán tại ô K6 và L6.
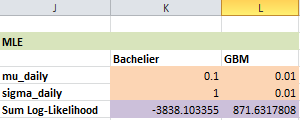
Để chạy Solver:
- Vào thẻ Data > Solver (nếu chưa có, bạn cần kích hoạt trong File > Options > Add-ins).
- Set Objective: Chọn ô
$L$6(chứa Log-Likelihood tính sẵn). - To : Chọn Max.
- By Changing Variable Cells: Chọn vùng
$IK$4:$K$5(chứa \(\mu\) và \(\sigma\) dự đoán). - Constraints: Nhấn Add thêm điều kiện
$K$5 >= 0.0001(vì biến động không thể bằng \(0\) hoặc âm). - Nhấn Solve.
Cả hai phương pháp hiệu chuẩn cho ta kết quả ước lượng \(\mu\), \(\sigma\) gần như giống hệt với phần Python.
3. Dự báo — Predicting
Nếu ở Phần 1 và 2 chúng ta đã hiểu về quá khứ, thì ở Phần 3 này, chúng ta sẽ dùng dữ liệu đó để xây dựng một “cỗ máy dự báo tương lai”.
Tại sao không dự báo một con số duy nhất cho giá cổ phiếu Apple vào ngày mai?. Câu trả lời là thị trường không phải là một bài toán cộng giản đơn. Giá cổ phiếu là sự kết hợp của xu hướng dài hạn và những cú va đập ngẫu nhiên đến từ tin tức, tâm lý đám đông, và các sự kiện vĩ mô.
Thay vì đoán mò một con số, chúng ta giả lập 10 000 “kịch bản tương lai” khác nhau: có kịch bản AAPL tăng vọt vì ra sản phẩm mới, có kịch bản AAPL lại giảm sâu vì suy thoái kinh tế. Kết quả là bạn không chỉ có một giá mục tiêu, mà là một “phễu xác suất” giúp bạn biết được vùng giá nào dễ xảy ra nhất.
3.1. Dự báo với Python
Trong phần này ta chỉ tập trung vào mô hình GBM thay vì cả hai mô hình như các phần trước. Tham số hiệu chuẩn được tính lại nhờ hàm stats.norm.fit và được chuyển về đơn vị năm mu_paramm, sigma_param.
# --- 6 Simulation Parameters ---
S_initial = df_prices['close'].iloc[-1]
dt = 1 / 252 # Time step (1 day)
n_steps = 90 # 90 trading days
n_simulations = 10000 # 10000 scenarios
# Parameters from calibration section
mu, sigma = stats.norm.fit(log_returns) # MLE
mu_param = mu * 252
sigma_param = sigma * np.sqrt(252)
Để mô phỏng bước đi của giá cổ phiếu trong 90 ngày tới, chúng ta chia nhỏ thành từng bước nhỏ (mỗi bước là 1 ngày). Ta áp dụng công thức tính giá như trong Bài 4. Brownian Motion.
\[S_{t+\Delta t} = S_t e^{(\mu - \frac{\sigma^2}{2})t + \sigma \Delta W_t}\]Tuy nhiên, chúng ta không chỉ mô phỏng giá ở vị trí cuối cùng \(S_T\) mà cần mô phỏng toàn bộ đường đi của giá cổ phiếu. Bước thời gian ở đây là \(\Delta t\) (1 ngày) thay vì cả khoảng thời gian \(T\).
# --- 7. Projection Random Paths ---
dW_t = np.random.normal(loc=0, scale=np.sqrt(dt), size=(n_steps, n_simulations))
# Calculate daily growth factors using GBM discretized formula
# Formula: exp((mu - 0.5 * sigma^2) * dt + sigma * sqrt(dt) * Z)
daily_growth = np.exp((mu_param - 0.5 * sigma_param**2) * dt +
sigma_param * dW_t)
# Accumulate growth over time to get price paths
simulated_paths = S_initial * np.cumprod(daily_growth, axis=0)
# Prepend the starting price S0 to each simulation path
simulated_paths = np.vstack([np.full(n_simulations, S_initial), simulated_paths])
Trước khi muốn biết tương lai như nào, bạn phải biết mình đang đứng ở đâu. Chúng ta vẽ biểu đồ giá quá khứ cho history_window = 252 ngày trước để có cái nhìn trực quan nhất.
# --- 8. Visualization ---
plt.figure(figsize=(10, 6))
# Plot historical data
history_window = 252 #252 days of history
historical_segment = df_prices['close'].iloc[-history_window:]
history_index = np.arange(-(history_window - 1), 1) #index from -59 to 0
plt.plot(history_index, historical_segment, color='blue', lw=1.5, label='Historical Price')
Thay vì chỉ vẽ một đường dự báo duy nhất, chúng ta vẽ ra 100 kịch bản ngẫu nhiên với vòng lặp for i in range(100). Ý nghĩa ở đây là: tôi không biết chính xác giá sẽ đi đường nào, nhưng đây là tất cả những con đường khả thi mà AAPL có thể đi qua.
# Plot simulation paths
future_index = np.arange(0, n_steps + 1) # Align projection with history
for i in range(100):
plt.plot(future_index, simulated_paths[:, i], color='red', lw=0.5, alpha=0.15)
# Plot confidence intervals
median_path = np.percentile(simulated_paths, 50, axis=1)
p5 = np.percentile(simulated_paths, 5, axis=1)
p95 = np.percentile(simulated_paths, 95, axis=1)
plt.plot(future_index, median_path, color='red', lw=1, linestyle='--', label='Forecast Median (P50)')
plt.fill_between(future_index, p5, p95, color='red', alpha=0.1, label='90% Probability Cone')
plt.axvline(x=0, color='grey', linestyle='--', alpha=0.5, label='Today')
plt.title(f"Historical Data and Monte Carlo Projection")
plt.xlabel("Days relative to Today")
plt.ylabel("Price")
plt.legend()
plt.show()
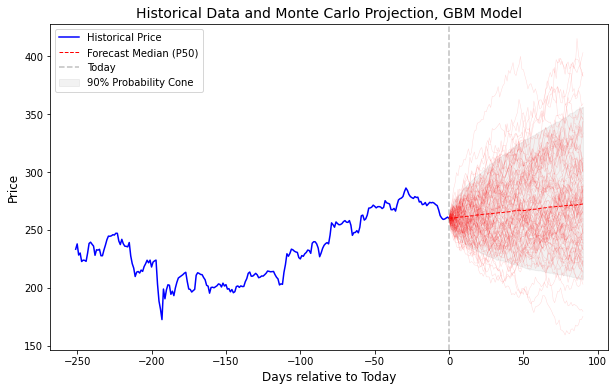
Biểu đồ phía trên là một bức tranh toàn cảnh về cổ phiếu Apple: từ thực tế trần trụi quá khứ (đường màu xanh) đến một tương lai đầy biến động được mô phỏng qua 10 000 kịch bản (những đường hồng nhạt).
-
Vạch đứt đoạn (Today): Đây là cột mốc phân chia giữa sự thật (bên trái) và giả thuyết (bên phải). Chúng ta chỉ có một quá khứ duy nhất, nhưng lại có vô vàn tương lai có thể xảy ra.
-
Phễu xác suất (90% Probability Cone): Vùng tô màu ghi nhạt chính là nơi mà mô hình tin rằng giá cổ phiếu Apple sẽ nằm trong đó với xác suất 90%. Bạn có thể thấy chiếc phễu này càng lúc càng loe rộng ra. Điều này phản ánh một quy luật tự nhiên trong tài chính: thời gian càng xa, sự bất định càng lớn.
-
Đường trung vị (Median): Đây là kịch bản “trung dung” nhất. Nó không quá lạc quan cũng không quá bi quan.
-
Đường ngoại lệ (Outliers): Hãy để ý có một vài đường hồng nhạt nằm hẳn ra ngoài vùng tô màu đậm. Đây chính là những kịch bản “thiên nga đen” (Black Swan) hoặc những cú đột phá bất ngờ. Dù xác suất thấp, nhưng mô hình nhắc chúng ta rằng: những điều không tưởng vẫn có thể xảy ra.
Giữa hàng ngàn kịch bản hỗn loạn, bạn sẽ chọn đặt cược vào đường trung vị ổn định hay chuẩn bị cho những kịch bản nằm ở rìa của chiếc phễu?
3.2. Dự báo với Excel/VBA
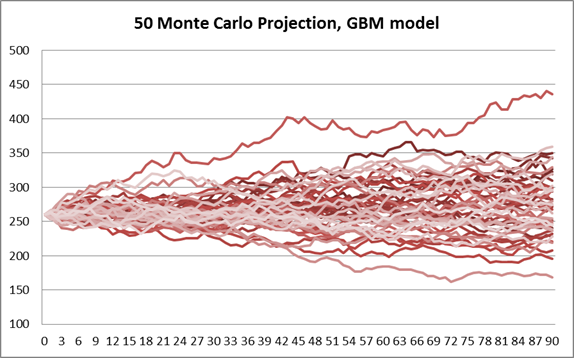
Worksheet 3 “Predicting”: Trang tính này thực hiện mô phỏng Monte Carlo dựa trên mô hình GBM để dự báo các kịch bản giá tiềm năng của cổ phiếu Apple trong tương lai.
Tham số \(\mu\), \(\sigma\) của mô hình GBM cùng giá cổ phiếu tại ngày cuối \(S_0\) được lấy từ trang tính “Calibration”. Từ các cột B:AY ta tạo 50 kịch bản đường đi khác nhau của giá cổ phiếu theo mô hình GBM.
Kịch bản đầu tiên, công thức tại ô B25 như sau.
=B24 * EXP(($B$2 - 0.5 * $B$3^2) * $B$5 + $B$3 * SQRT($B$5) * NORM.S.INV(RAND()))
Hàm NORM.S.INV(RAND()) chỉ giúp sinh số ngẫu nhiên tuân theo phân phối chuẩn hóa (Standard Normal Distribution) với \(\mu = 0\), \(\sigma = 1\), chứ không phải phân phối chuẩn (Normal Distribution) với \(\mu\), \(\sigma\) bất kỳ.
Để tạo \(\Delta W_t \sim N(0, \Delta t)\) — phân phối chuẩn với độ lệch chuẩn \(\sqrt{\Delta t}\), ta cần viết lại công thức như sau \(\Delta W_t \sim \sqrt{\Delta t} \times N(0, 1)\). Số ngẫu nhiên \(Z \sim N(0, 1)\) được tạo ra nhờ Excel, và khi nhân với \(\sqrt{\Delta t}\) ta sẽ được \(\Delta W_t\). Ta có công thức tính giá GBM:
\[S_{t+\Delta t} = S_t e^{(\mu - \frac{\sigma^2}{2})t + \sigma \Delta W_t} = S_t e^{(\mu - \frac{\sigma^2}{2})t + \sigma \Delta t Z}\]Dưới đây là biểu đồ 50 kịch bản ngẫu nhiên của giá cổ phiếu Apple. Bạn có thể nhấn phím F9 trong Excel để thay đổi các kịch bản ngẫu nhiên khác.
4. Tóm tắt và thảo luận
Trong bài viết này, chúng ta đã đưa mô hình Bachelier và GBM ra khỏi những trang sách giáo khoa để đối mặt với dữ liệu thực tế nghiệt ngã của thị trường.
-
Thực tế không bao giờ hoàn hảo: Bài học lớn nhất là dữ liệu thực tế luôn vi phạm giả định của mô hình. Bachelier và GBM giả định dữ liệu tuân theo phân phối chuẩn, nhưng thị trường luôn có hiện tượng “đuôi béo” (Fat Tails) — các sự kiện cực đoan xảy ra quá mức thường xuyên, và “đỉnh nhọn” (Leptokurtosis) — lợi nhuận thực tế thường bị lệch về một phía.
-
Dữ liệu là “DNA” của mô hình: Việc hiệu chuẩn (calibration) các tham số \(\mu\) (drift) và \(\sigma\) (volatility) từ dữ liệu thực tế giúp chúng ta tạo ra mô phỏng mang đậm “tính cách” riêng của cổ phiếu thay vì một con số ngẫu nhiên vô nghĩa.
-
Định lượng rủi ro: Thay vì dự đoán một mức giá mục tiêu duy nhất, phương pháp Monte Carlo cho phép chúng ta nhìn thấy hàng ngàn tương lai có thể xảy ra. “Phễu xác suất” (Probability Cone) giúp chúng ta xác định được “vùng an toàn” nơi 90% các kịch bản có thể xảy ra.
Chúng ta chấp nhận rằng Bachelier và GBM không hoàn hảo để đổi lấy sự đơn giản và khả năng tính toán nhanh chóng. Hiểu được rằng thực tế không tuân theo phân phối chuẩn chính là bước đầu tiên để bạn trở thành một nhà đầu tư thận trọng và thông minh hơn.